Architecture Tradeoffs Across the Agentic Spectrum
I’ve been missing a couple of weekends now as I was working towards this post, but life gets busy. This was a fun experiment and a lot of learning.
The age of abundance
Elon Musk has been predicting an age of abundance driven by AI and robotics. For software engineers, that abundance is already here, at least in the narrow sense that code is cheap to produce in 2026. AI coding tools handle the routine work, and people are starting to claim that a single senior engineer with AI assistance can output what used to require a small team. Maybe. I don’t think we know the full shape of it yet, but the pressure is real and the old architecture questions still matter. Addy Osmani calls this the next two years of software engineering. Gergely Orosz is tracking the real impact on working engineers. This post frames it really well: abundance is cheap, trust is not.
When code becomes cheap, architecture becomes more valuable. The decisions around the code, cost vs. quality, stateless vs. stateful, deterministic vs. probabilistic, become even more important because bad architecture compounds faster when you can produce code this quickly.
I wrote about this earlier as software engineering being a craft. As I get more into Applied AI and agents professionally, I built four small projects across the agentic spectrum on free-tier infrastructure, partly because I wanted to understand the tradeoffs and partly because I learn best by breaking my own toys. The surprise was how familiar the decisions felt. Every architecture choice I made was one I’ve been making for a long time.
Tinkering around
When I built the first project, I genuinely thought I was building an AI agent. It generates images, writes captions, publishes them, it’s using AI, so my naive sense was it is agentic. It took me a while to realize it was a cron job with an API call. I work on adopting AI-native workflows professionally too, so that gap between what I assumed and what I’d actually built was a lesson for future me. I’ve always learned by building, so this was another one of those lessons that sticks because I learned it the hard way.
A decision framework
I made this after the fact while messing around with Excalidraw MCP. I wrote down the questions I kept asking myself, then turned them into a picture. The first one matters more than the rest: can you write down every step your system will take before it runs?
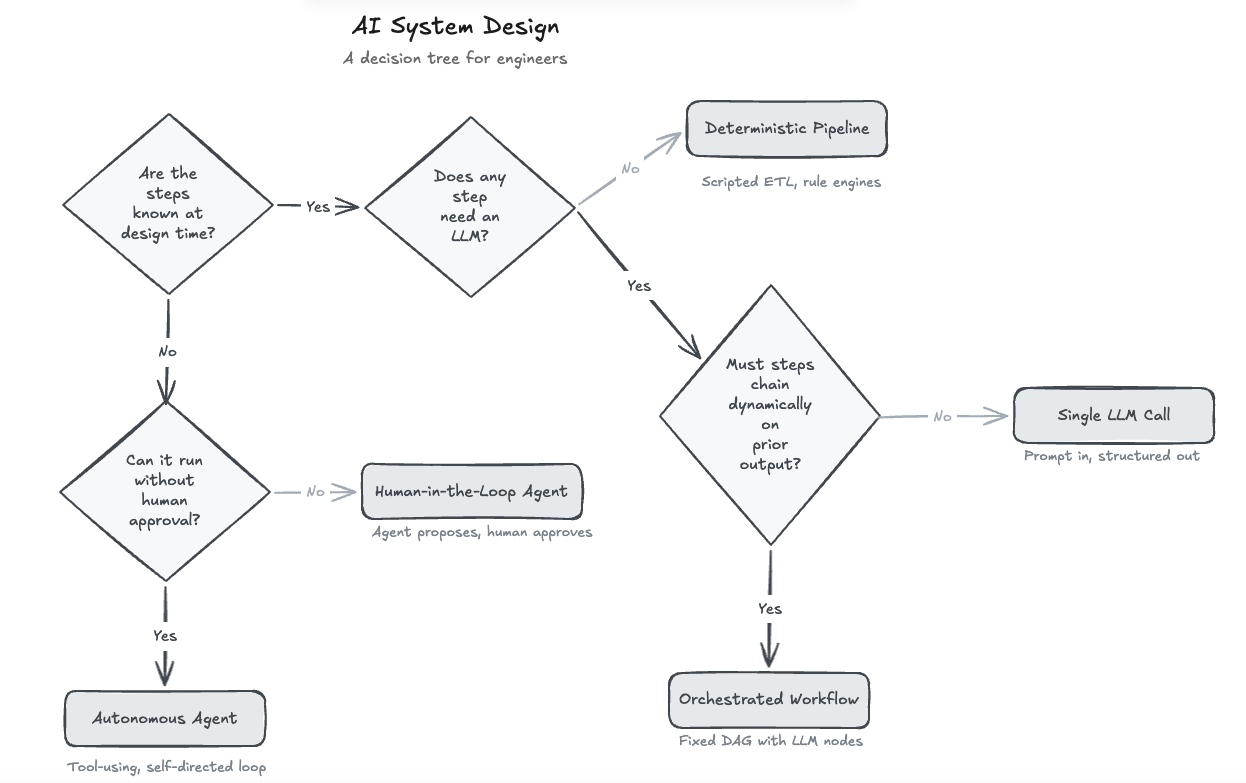
| Architecture | When to use | My example |
|---|---|---|
| Deterministic Pipeline | All steps known, no LLM needed | Cross-Publish Pipeline |
| Single LLM Call | One step needs AI, no chaining | Daily Sea Lion |
| Orchestrated Workflow | Multiple LLM steps, fixed order | Case Closed |
| Autonomous Agent | Steps unknown, low-risk actions | Music Trivia Agent |
| Human-in-the-Loop Agent | Steps unknown, high-risk actions | This is most interesting in the enterprise space |
My weekend journeys
1. Deterministic Pipeline
If every step is known at design time and none of them need an LLM, you don’t need AI infrastructure. You need a script, a rule engine, or plain old automation. Adding an LLM here is overhead with no upside.
My example: My cross-publish pipeline syndicates blog posts to Dev.to and Hashnode. A regex-based sanitizer transforms MDX into platform-specific markdown, a JSON file tracks what went where, and GitHub Actions runs the cross-publishing job. No LLM anywhere. It’s boilerplate code, but it never hallucinates. In the age of abundance, knowing when NOT to use AI in your application is as important as knowing when to use it.
The engineering parallel: This is the build-vs-buy decision as it has always been. Can a regex handle this? Then don’t wire up an API call that costs tokens, adds latency, and might change your words. Deterministic pipelines are boring on purpose. AI-assisted coding is useful here because it helps you write the boring parts faster without making the runtime system smarter than it needs to be.
2. Single LLM Call
If you need AI for one step and the output doesn’t feed into another LLM call, keep it simple. You write the prompt and ask for structured output. This covers classification, extraction, summarization, and most “add AI to this feature” use cases. It’s cheap, fast, and easy to debug. I would default to this unless there’s a real reason to add more machinery.
My example: Daily Sea Lion generates a sea lion image and caption every morning. Pollinations AI produces the image, Groq/Llama 3.3 70B writes the caption, and the script publishes to Cloudflare Pages. The two LLM calls don’t talk to each other. The caption doesn’t evaluate the image, it just adds a stylistic quote to it.
The tradeoff I made: No quality gate. Prompt constraints substitute for an eval loop. I hardcoded 14 image prompts across moods and the caption prompt bans common failure modes (“No awww or adorable”). Good prompts do some of the work that an eval loop would do if I could afford one. The AI assistance was most useful while tightening those prompts, not while running the final workflow. With budget, I’d generate 3 candidates and use a cheaper model to pick the best. Same cost-vs-quality shape as sizing a cache.
3. Orchestrated Workflow
When multiple steps need an LLM but the execution path is fixed, you’re building a graph (DAG to be specific) with LLM nodes. You control the graph, the LLM controls the content at each node. I think of it as a fixed pipeline where some stages happen to be AI-powered. You get room for generation without giving up the ability to reason about the system.
My example: Case Closed is a detective game. A 70B model generates the mystery once (culprit, clues, red herrings, suspect secrets), then those outputs feed into per-character system prompts that an 8B model uses for chatting with the player as they investigate. The expensive generation step sets up the later conversations. That’s a fixed dependency, not a runtime decision.
The tradeoffs I made:
Dual-model routing. 70B for generation (one call, quality matters), 8B for conversations (many calls, speed matters). ~10x cost difference. If you think of it as pre-compute vs. runtime, the expensive batch job generates the config once and cheap lookups serve it at request time.
Templated responses for 5 of 6 scenarios. Only the AI-generated “Surprise Mystery” uses live LLM calls for conversations. Cut costs ~80%. It’s the same as caching: if the answer doesn’t change, don’t recompute it.
Server-side secrets. Culprit never sent to the client, anti-cheat rules in the system prompt, regex sanitizer strips leaked answers. The security gates don’t change just because the service behind them is an LLM.
Serverless blocked the next pattern. I wanted suspects to consult each other between rounds. Cloudflare Pages Functions are stateless: one request, done. Anyone who’s worked with stateless microservices knows this constraint. This led me to Durable Objects for the agent.
4. Autonomous Agent
When the steps aren’t predictable at design time, you need an agent that reasons about what to do next. It calls tools, stores the data it needs, evaluates results, and iterates in a self-directed loop. This is where the demos start to feel a little magical, and also where debugging gets annoying fast. You’re trading predictability for capability, so you need budget controls. An open-ended loop with no ceiling is just a tiny machine for burning tokens.
My example: The Music Trivia Agent takes a YouTube link and hunts for the most surprising fact about the song. It runs a custom observe-think-act loop on Cloudflare Workers + Durable Objects: Plan → Search (DuckDuckGo) → Extract → Evaluate (1-10 surprise score via Claude Haiku 4.5) → Decide (continue or synthesize). I don’t know how many iterations it’ll take when I hit “go.”
The tradeoffs I made:
Durable Objects solved what serverless couldn’t. Stateful container with SQLite that stays alive across requests. Think session-affinity, but at the edge. Exactly what Case Closed needed but couldn’t have due to my tradeoff there.
Budget controls shape the architecture. 8 iterations max, 20 LLM calls max, ~$0.007/session average. Score 8+ stops immediately, 7+ after 2 iterations stops. A solid 7 in hand beats chasing a 10 that might not exist. Every agent needs a cost ceiling, the question is where you set the threshold for “good enough.”
Haiku for everything, not a model cascade. Tried the cheap-model-for-tools, expensive-for-synthesis split. Routing complexity wasn’t worth it. With budget, I’d use Sonnet for evaluation only. Sometimes spending more per unit reduces total spend by enabling earlier stops.
Prompt-based evaluation, not a classifier. System prompt defines the surprise scale with examples. Bigger risk is circular searching, I’ve watched it search “Beatles recording sessions” three slightly different ways before trying a new angle. In my testing, I saw it struggle with Indian regional music, so I added genre-specific sources it could branch into when the generic web results were thin.
Input/output sanitization. Prompt injection filtering on metadata, hallucinated-URL stripping on output. Hallucination was the biggest risk I hit in practice, so this is where eval loops earn their keep. No different from validating user input in any web app, and it’s not optional for agents that read from the open web.
5. Human-in-the-Loop Agent
When the steps aren’t predictable AND the actions carry real consequences, the agent proposes actions but a human approves before execution. That’s the right call for anything involving money, people, external communication, data deletion, or irreversible changes. An agent that asks for approval is more valuable than one that guesses right 95% of the time when the other 5% sends an email to the wrong customer. And if you add an “Always Allow” button, then auditing stops being optional.
I haven’t built one of these in my hobby projects yet, but I know what questions I’d ask first. My Music Trivia Agent is autonomous because the worst case is a controversial surprise trivia fact. If it were sending results to a social media API or writing to a production database, I’d add an approval gate before the final action. The agent loop stays the same, you just insert a checkpoint before execution. The engineering pattern is the same one we use whenever we separate “plan” from “commit”: database transactions, deployment pipelines, two-phase commits. The tool is new, but the engineering principle isn’t.
The boundary shifts over time. Today’s human-in-the-loop agent can become tomorrow’s autonomous agent once you’ve built confidence through logs, audits, evals, and a few boring production weeks. Start with the approval step, then earn the right to remove it.
Same ol’ same old
Each tradeoff in this post maps to something I’ve done before: cost-sensitive routing between services, choosing deterministic logic over something smarter, picking the right persistence model for the execution pattern, threat modeling the parts that touch untrusted input, and caching where the answer doesn’t change. We’re in an age of abundance when it comes to producing code, but the engineering judgment that decides what to build, how to constrain it, and when to keep things simple? That’s not abundant. That’s scarce, and it’s the same craft it’s always been.
I’m curious what’s next, maybe multi-agent coordination or agents with memory across sessions. I don’t know yet, but I’ll build it before I form an opinion.
Scaling all of this to a team of more than 1 is a topic for another day. I keep wondering what happens to team dynamics when your first thought partner is an AI friend and maybe one or two people you ideate with early, while the rest of the group joins much later in the building journey. That feels exciting, but also a little weird, and I don’t think we have the rituals for it yet.
These are my personal thoughts, experiences, and opinions, and they do not reflect the views of the company I work for.